 Being only twenty-one years old, I’ve pretty much grown up with technology. While I do remember the brutal days of dial up, when texting didn’t exist and I had to actually remember a phone number, I have been pretty thoroughly connected with technology since I was young. I received my first cell phone for my eleventh birthday a little over ten years ago—a Nokia with a tiny, blue screen, with the most advanced features on this little phone being the games ‘Snake’ and ‘Doodle’. I remember the popularity of Napster and Limewire, both being controversial yet game changing methods of exchanging content and information. I remember using AOL Instant Messenger as a way to stay connected with my friends. I remember playing PlayStation with my dad and thinking about how cool it would be to be able to somehow play against my friends even though they were not with me.
Being only twenty-one years old, I’ve pretty much grown up with technology. While I do remember the brutal days of dial up, when texting didn’t exist and I had to actually remember a phone number, I have been pretty thoroughly connected with technology since I was young. I received my first cell phone for my eleventh birthday a little over ten years ago—a Nokia with a tiny, blue screen, with the most advanced features on this little phone being the games ‘Snake’ and ‘Doodle’. I remember the popularity of Napster and Limewire, both being controversial yet game changing methods of exchanging content and information. I remember using AOL Instant Messenger as a way to stay connected with my friends. I remember playing PlayStation with my dad and thinking about how cool it would be to be able to somehow play against my friends even though they were not with me.
This past October for my twenty first birthday, I received what is probably my tenth cell phone—an iPhone 6 with a touchscreen and a multi-pixel digital camera that keeps me constantly connected with the rest of the world and allows me to access any information I want in just a few seconds. I am now using iTunes to buy the latest music, videos, books, games, and applications, as well as using Spotify to stream unlimited music directly to my phone and MacBook Pro. I have a social presence on LinkedIn, Twitter, Facebook, Instagram, Snapchat, and Pinterest, where I can connect with just about anyone, anywhere, anytime. I can now watch my friends play people from the other side of the world in real-time, online video games while I’m video chatting with my best friend who is stationed outside of the United States. In ten short years of my life, this is how much technology has evolved in front of my own eyes. Plus, this does not even take into account the emergence and growth of other technologies and sources of information that have changed our lives. In just ten years, the world has seen an exponential increase in the complexity, sophistication, integration, and importance of, as well as the reliance on, technology. This leads me to ask the question, what will technology be like in ten years and how is it going to change our lives?
Time Magazine recently just published an article called “This Is How Tech Will Totally Change Our Lives by 2025”, which was based off a report recently released by the Institution for the Future which listed five predictions for the ways tech is going to change our lives in the next ten years. The driving force behind how technology is going to change our lives isthe “ever-increasing hunger for data” which will “fundamentally change the way we live our lives over the next decade.” According to the Times article, “in the future, people might be able to personally sell info about their shopping habits, or health activities to retailers or pharmaceutical companies,” which means that we might possibly see an economical shift in which personal data will be able to be shared, bought, or sold with more benefits to the consumer. With the introduction of the first directional shift, the information economy, individuals will be able to choose what they do with their information, therefore possibly leading to more opportunities for both individual, and widespread, financial or social gain.
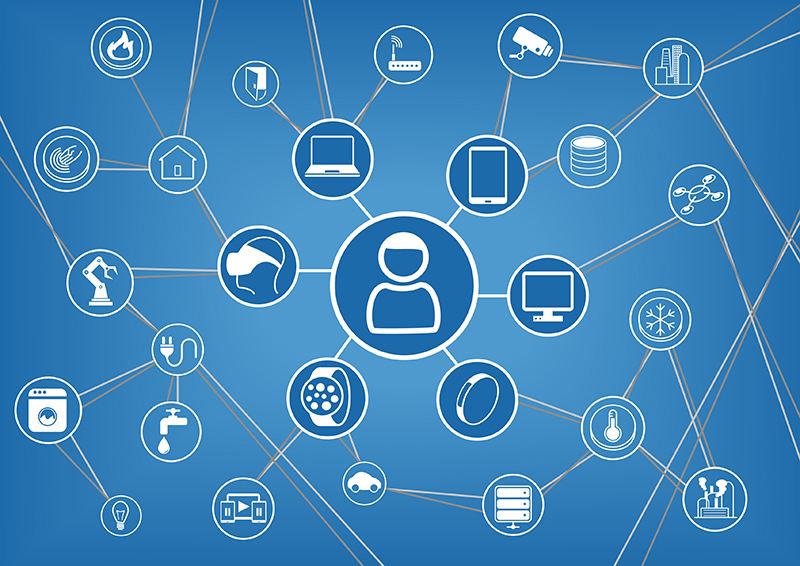
Stemming from the increased dependence on data and the shift to an information economy, we will definitely see networked ecosystems, such as the Internet of Things continue to expand. The Internet of Things is described as a network of physical objects, from basic household items to cars, which are embedded with technologies that enable an exchange of data via the internet. Could you imagine waking up one morning to your alarm clock which is connected to your smart phone, which then sends a message to your shower to turn on? Then after you turn off the shower, a message is sent to your coffee pot to start brewing a cup, which then signals to turn on the kitchen lights and flip the television to the morning news? Or how about having your refrigerator identify when you are low on milk so that it can send you a reminder on your way home from work to pick some up after you pick the kids up from school? All of these instances seem a bit foreign right now; however, we’re already seeing and experiencing the beginning of the Internet of Things. The cross compatibility of all of these inanimate “things” promises to make our lives easier, more efficient, and possibly even safer. We’ve already began to see self-driving cars start to become a reality and these will likely revolutionize not only the automobile industry, but how we get from place to place, the numbers of accidents on the roadways, insurance costs, and many other facets of our lives.
While the Internet of Things may gather information about our daily decisions, the third shift caused by the information generation is the continued creation of increasingly sophisticated algorithms which may end up actually aiding our daily decisions at work. In the article “2025 Tech Predictions Both Thrilling and Scary”, it is stated that “tech leaders increasingly are saying that we’re moving to a world where employees will have smart decision-support systems.” These smart decision-support systems operate under what is known as augmented decision-making. Augmented decision-making is referred to by Daniel J. Power as, “when a computer serves as a companion, advisor and more on an ongoing, context aware, networked basis.” So while data analytics have given us information to base future decisions off of, what augmented decision-making and its systems do is offer real-time information, basically in the form of suggestions in order to help individuals make important decisions. Having these support systems will be like having a second opinion for everything; however, the algorithm produced information given will be optimal and will likely be more accurate than another human being would. This however, causes me to raise one important question; how long can these systems assist in decision making before they eventually replace the workers outright? While I think there are certainly fields that can benefit from this, such as the medical field where a doctor could use these tools to determine a more accurate prognosis, there are some jobs that could completely be replaced by these systems and this could have a profound effect not only on people’s lives, but also on our economy.
The fourth predicted shift is known as “multi-sensory communication.” In this shift, information will be able to be communicated and received through multiple human senses. We can see an example of this in the recently released Apple Watch. Instead of ringing or vibrating, the watch will actually “tap” an individual on their wrist to let them know when they have a text or a notification. In the Institute for the Future’s report, it expands on multi-sensory communication by stating, “in a world saturated with competing notifications, multi-sensory communication of information will cut through the noise to subtly and intuitively communicate in novel ways that stimulate our senses.” The addition of senses such as touch, smell and taste, as well as new experiences with sight and sound, will not only change the way we communicate socially, but it will also change how developers, retailers, and marketers create products and appeal to customers. What this change will ultimately mean is that we will begin to stray away from the screens we hold and physically interact with, and transition to what the Institution for the Future describes as “screenless communication tools that allow people to blend the digital and physical in more fluid, intuitive ways.” The idea of blending the digital and physical can be seen in the immersive marketing tactic that the Marriott Hotels launched in late 2014 called ‘The Teleporter.’ The Teleporter is a virtual reality experience that was programmed to allow users to “experience” and virtually transport to Hawaii or London. The technology featured a virtual headset and wireless headphones, along with several sensory triggering features such as producing heat, wind and mist, all working in sync to give the user a realistic experience of what it is like to be on the beaches of Hawaii or strolling through London. While this marketing strategy seems to be a bit over the top right now, we will definitely be seeing similar tactics being used in the next ten years both inside and outside of our homes.
After all of this talk about sharing data and personal information and how it is going to transform life as we know it, I’ll introduce the fifth, and in my opinion, the most important shift: privacy enhancing technology. With the vast amount of data that will be produced and received, there will be a demand for better tools for privacy and security. There must be a common ground found between the individual users who are concerned about their privacy and the companies leveraging their data in order to make sure that people’s information is protected and innovation does not cease because of personal exposure. There are predictions of “cryptographic breakthroughs” which will hopefully help in minimizing the number of hacks and breaches on companies and individuals, as well as continuous changes and updates to policy that will ensure protection to both the producers and consumers. It is a must that privacy is continuously advancing while the amount of data being shared concurrently increases, because if not then all of our lives will essentially become openly available to anyone, and that is terrifying.
The information generation is upon us. We have already began aggregating, analyzing and using data and information to enhance our lives. With the digital and physical worlds beginning to come together in other places besides computers and cellphones, we are in for an innovative, exciting, and possibly even scary next ten years where the only things that are certain are uncertainty and data. I’m curious to see where I am at in 2025. I’m interested in what my cellphone, if they even exist anymore, will look like and what it can do. I’m a bit nervous about the fact that policy tends to not be able to keep up with the speed of technological innovation. I am excited to see how companies will incorporate all of our senses into technology and how this might enhance and change our lives. How am I going to be using technology at home, at work, in social settings? It is going to be unlike anything that any of us have ever experienced before, but I am very interested in seeing how much technology is going to change in front of my eyes over the next ten years.