As sites like viz.wtf illustrate, there are many ways to create confusing and misleading data visualizations. There are also many common design-choice options that might be considered sub-optimal. This post outlines 7 common “mistakes”, with alternative solutions that avoid them. It is a personal selection and is certainly not definitive. The data used is all fictitious and the chart labels are somewhat arbitrary, acting primarily as illustrative placeholders.
Don’t use a chart when a sentence will do
Probably the most fundamental question to ask yourself when designing charts: “Is a chart even warranted?”. The great advantage of data visualization is in seeing patterns that aren’t obvious when looking at printed numbers. But how likely is it that you’ll miss a key pattern when your data consists of only a couple of values (left)? A sentence (right) is much quicker to create, takes up less space and uses less ink than a chart. There’s no requirement to think of informative titles or axis labels and no chance that the data will end up well-separated from the context in which it is discussed.

Even if you have a larger number of data points it is still not necessarily the case that a chart is your best option. If your goal is to display values precisely in an easy-lookup format then the structure a table provides is likely the optimal solution.
Don’t go overboard with the vibrant colors
It’s very easy to make a chart pop-out from the page by using large blocks of intense color. Eduard Imhof described why this is a problem for maps in “Cartographic Relief Presentation”:
“Pure, bright or very strong colors have loud, unbearable effects when they stand unrelieved over large areas adjacent to each other, but extraordinary effects can be achieved when they are used sparingly on or between dull background tones.”
The quote applies across other areas of data visualization too. One of the worst offenders is the multicolored bar chart (left) when the colors provide no additional information. We have a glaring array of reds, greens and blues, an apparent encoding of a non-existent variable and no easy way of highlighting something we want to bring particular attention to. If you use modest colors for the bulk of the data and especially the supporting structure of the chart (axes, gridlines etc) then the strongest, most vibrant color(s) can be used to emphasize something particularly important (right).

Things are somewhat different when the data encoding leads to small patches of color, for example points on a scatterplot. In such cases we are less sensitive to the color differences between the small patches. Using higher saturation colors will help to alleviate this problem.
Don’t chop off the bottom of your bar charts
This is another way of saying “always start the bars in your bar charts at 0″.
The beauty of a well-designed bar chart is that, as well as making judgments based on position along a scale, we can directly compare the lengths of any two bars to judge relative magnitude. This relies on the lengths being proportional to the magnitudes of the values encoded and fails completely when they’re not (top left). It’s not just that removing this proportionality removes this feature, but also that the user of the chart is likely to expect that proportionality to exist. This leads to misjudgments of the data and that is worse than no data at all.
This distortion is often used deliberately to mislead and, as a result, even an innocent slip may lead to questions about intent and integrity. There is almost always a better alternative for the honest designer, even when the data concerned show only small variation around some comparatively large number (top right). Line charts are an obvious alternative for continuous data, while dot plots can be useful for discrete data (bottom left). A different approach is to transform the data, for example, by subtracting a “target” value from each data point or inverting the measure plotted (bottom right). (Obviously one needs to be careful that the salient message remains in tact here.)
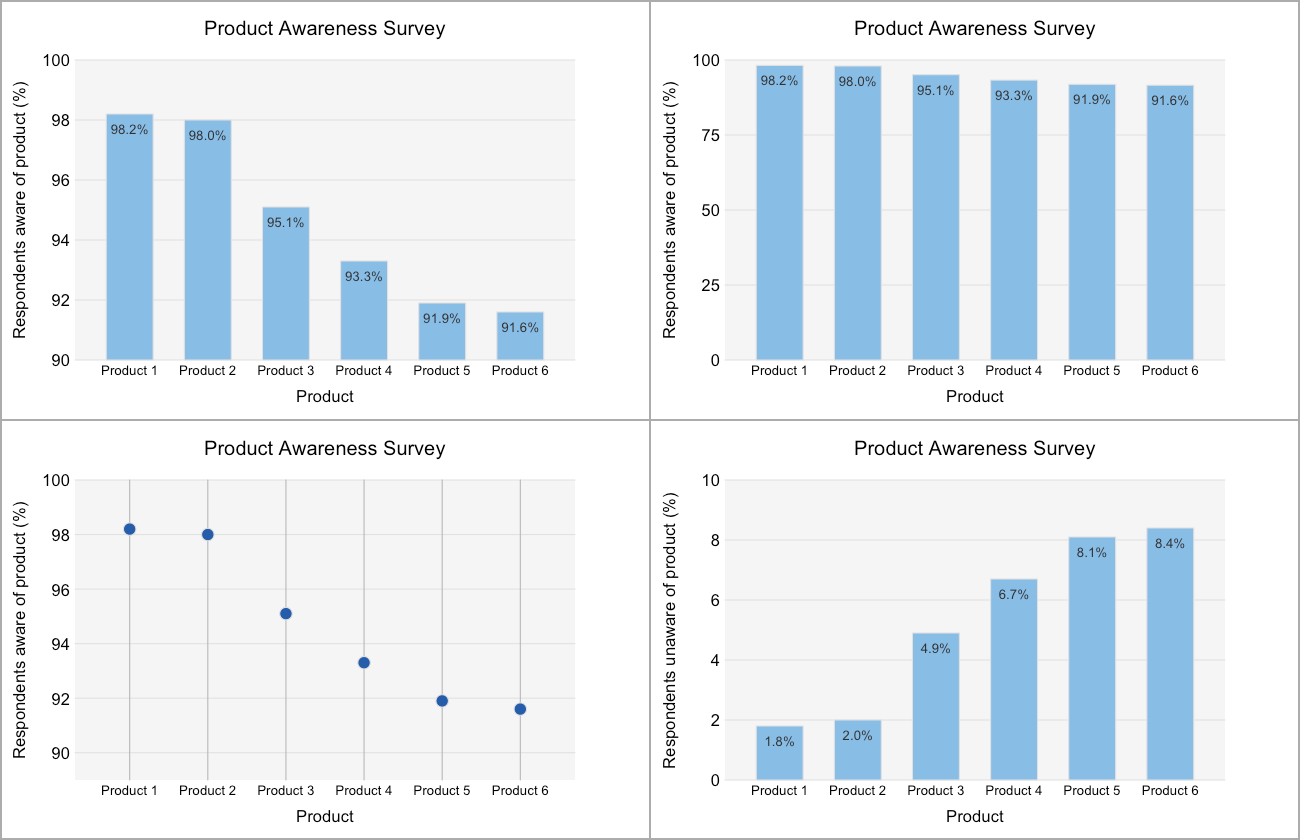
Rules in data visualization are there to be broken. Make sure you have a very good reason for doing so here.
Don’t use two lines when one will do
This problem is more nuanced than the last and highly dependent on what it is you want to show.
Suppose you have two time-series data sets you want to compare. They have the same units and are roughly similar in magnitude. One option is to plot both lines on the same chart (left). We can see which is higher or lower at any given point in time, observe gradients and see anomalous points. There is absolutely nothing wrong with this and in many cases it is an ideal solution.
However, if what you really want to show is the magnitude (and sign) of the difference between the two time series then your best option is to plot that difference directly (right). The line then encodes the magnitude of this difference, with no requirement for the user to estimate the difference at each point in time.

Cleveland and McGill found a more fundamental difficulty with visually estimating the distance between two lines: “[t]he problem is that the brain wants to judge minimum distance between the curves in different regions, and not vertical distance”. Not only is comparing two lines a slower and more complex task, you’re more likely to get it wrong.
Don’t use a stacked area chart when you want to show individual components accurately
The difficulties we have interpreting differences from pairs of lines extends to stacked area charts. Both the bottom area and the total combined areas of stacked area charts are easy to understand because the horizontal axis provides a distinct, steady baseline. By contrast, the baseline for all the other area components must be constructed mentally, subtracting the shape of the underlying layers from the one of interest. I find this particularly difficult if the overall trend of the underlying layers is opposite to the layer of interest. For example, if the underlying layers trend strongly downwards, the shape of the layer of interest can resemble a (fat) downward sloping line (the Type III area, left). Even though the layer of interest may be getting fatter, the overall impression is of something decreasing when it is actually going up.
If you want your users to get a good sense of the data for the individual components you’re better off using distinct lines, either on a single pair of axes (right) or as small multiples. In the example below we can see magnitudes, gradients, line crossings and the relative sizes of fluctuations more clearly when the categories are plotted as separate lines.

Stacked area charts do have one very good application, namely when you’re interested in showing an ordered sum of components that changes (usually with time). One example of this would be illustrating how the total cost of a pint of milk changes due to fluctuations in farming, processing and retailing costs.
Don’t forget about your users with color vision deficiencies
Color vision deficiency (CVD) is the formal name for what is frequently described as color blindness. The most common problem associated with CVD is difficulty distinguishing reds from greens and is of genetic origin. It’s more prevalent in men (about 1 in 12 suffer) than women (about 1 in 200 suffer).
In western cultures green has come to be associated with “good” things or “go” and red with “bad” or “stop”. As a result of this it can be tempting to use these two colors to distinguish positive and negative outcomes (top left). However, because of CVD, some of your audience is likely to struggle to distinguish these two encodings.
If you only have two categories to encode then a simple solution is to swap green for blue (top right). If you have many categories (bottom left) then you’ll probably have to find a different solution. For example, if you’re plotting points you can change the shape of the points alongside the color (bottom right). This can be seen as redundant (but not harmful) encoding for the majority of your audience but likely essential for those with CVD.

It’s important to note that red-green CVD is more complex than just an inability to distinguish red from green. Color perception is altered in a broader sense, beyond that of those two specific named colors. For non-sufferers it’s thus extremely helpful that there are options for simulating the effects of CVD. Photoshop offers protanopia and deuteranopia (both forms of red-green CVD) filters, the Vischeck website also allows for red-green and blue-yellow CVD simulation of supplied images, and the Color Oracle application will momentarily simulate both red-green and blue-yellow deficiencies for the entire contents of your monitor.
Don’t obscure the data
Background gradients (left) or images can make your data visualization look more interesting and stand out from the page but are unlikely to help your reader draw any more insight from it. They are more likely to be a distraction and effects like simultaneous contrast (which gives rise to some notableopticalillusions) may lead to misperception. In general, keep to a neutral, single-color, background.

Want to learn more? Be sure to register for our upcoming webinar: How to Choose the Right Chart for Your Data, on March 11th. Click the banner below for more info!
